Figuring out how to extract data from PDFs is not an easy task. It can be quite a technical task and getting help from the tech team in your company is often like squeezing blood from a stone. If you’re looking to get the best out of your contracts you’ll most probably get to a point that reviewing full length contracts every time you need information just becomes massively time consuming. Contract management inefficiencies can cause a lot of difficulties in scaling. Extracting contract data from PDFs will help you to scale this as you pass the point of having thirty or forty customers. Challenges that will stall your growth if you don’t solve this problem will include lengthy contract negotiations, managing legal teams efficiently and not wasting time on post-signing struggles accessing vital information in lengthy PDF contracts.
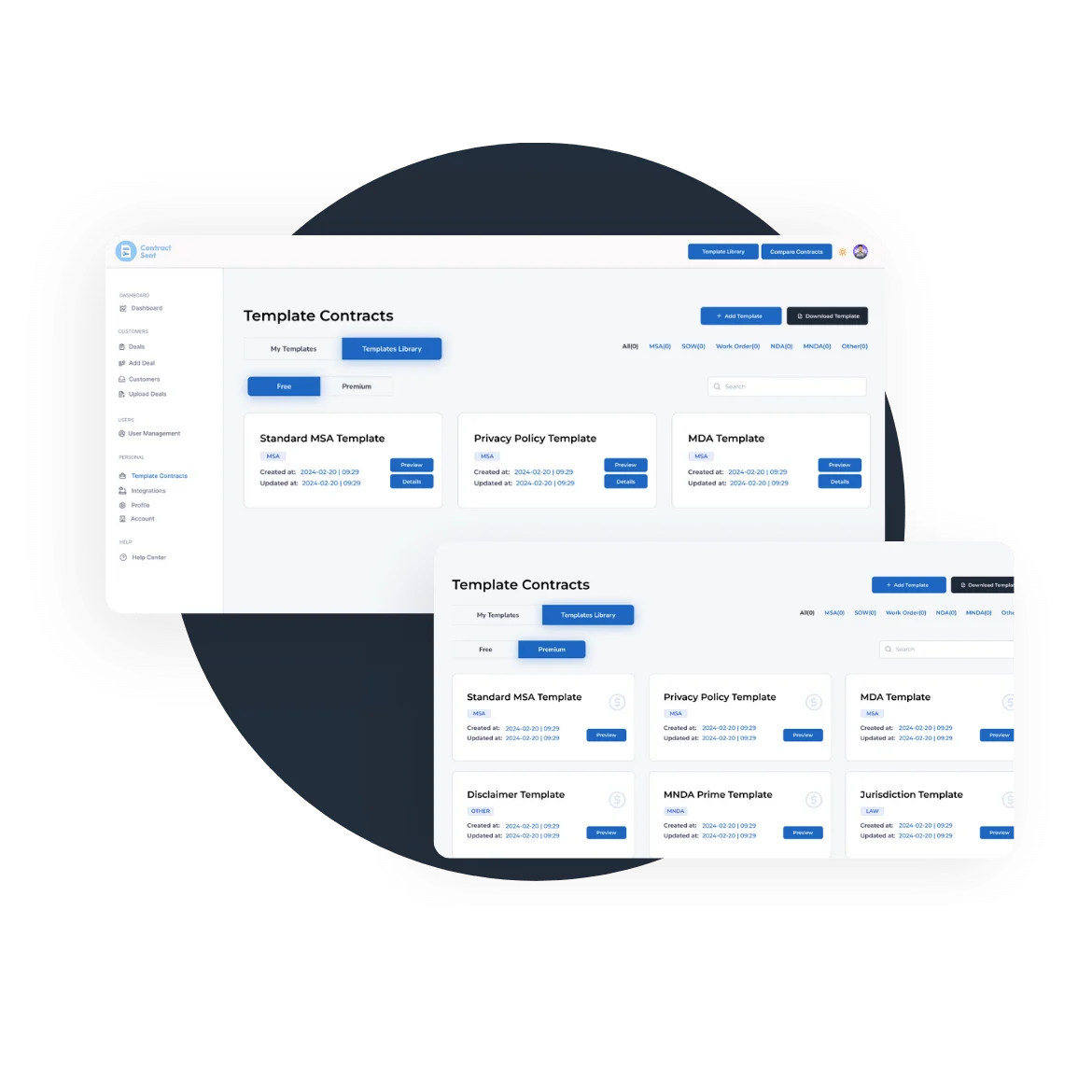
Contract Details – Extract Data From PDFs – What to Extract
Creating structured data to store essential details from your contracts is a smart practice for effective contract management. Here’s a list of contract details that would be useful to extract and maintain for reference:
- Contract Information:
- Contract Title
- Contract Number or ID
- Contract Date (Start and End)
- Renewal Dates
- Parties Involved:
- Contracting Parties (Your company and the SaaS provider)
- Contact Information for Key Contacts on Both Sides
- Contract Terms:
- Service Description
- Scope of Services
- Usage Limits (if any)
- Termination Clauses
- Force Majeure Provisions
- Financial Details:
- Contract Value
- Payment Terms
- Invoicing Schedule
- Late Payment Penalties (if applicable)
- Auto-Renewal Terms and Pricing Changes
- Service Level Agreements (SLAs):
- Performance Metrics
- Uptime Guarantees
- Support Response Times
- Escalation Procedures
- Data Security and Privacy:
- Data Handling and Storage Practices
- Security Measures Implemented by the SaaS Provider
- Compliance with Data Protection Laws
- Intellectual Property:
- Ownership of Data
- License Terms
- Usage Rights
- Confidentiality and Non-Disclosure:
- Confidentiality Clauses
- Non-Disclosure Agreements
- Insurance and Liability:
- Insurance Requirements
- Indemnification Clauses
- Compliance and Regulatory Requirements:
- Compliance with Industry Standards
- Adherence to Regulatory Requirements
- Dispute Resolution:
- Dispute Resolution Mechanisms
- Jurisdiction and Governing Law
- Contract Amendments:
- Procedures for Contract Modifications
- Change Control Processes
- Termination and Exit Strategy:
- Termination Conditions
- Notice Periods
- Data Retrieval and Transition Assistance
- Audit Rights:
- Provider’s Right to Audit
- Your Right to Audit the Provider
- Miscellaneous Provisions:
- Governing Law
- Entire Agreement Clause
- Amendments and Waivers
- Renewal and Cancellation Procedures:
- Renewal Notification Process
- Cancellation Procedures
- Training and Support:
- Availability of Training Resources
- Support Channels and Availability
- Service Changes and Updates:
- Notification Processes for Changes
- Procedures for Software Updates
By maintaining a comprehensive database with these contract details, you’ll have a centralized and organized reference point for quick access to critical information. Regularly updating this when you negotiate a new customer ensures that your team is well-informed and can effectively manage the contracts throughout their lifecycle. Now let’s get into the specifics of how to extract data.

Redline What Matters
Raise Changes For Approval To Turnaround Contracts Faster
Understanding the PDF Structure
Before diving into extraction methods, it’s crucial to comprehend the underlying structure of a PDF. Unlike plain text documents, PDFs are designed to preserve formatting, fonts, and layout. This makes extracting information directly from the file a bit tricky.
A PDF document typically comprises a series of objects such as text, images, and annotations, organized into pages. To extract data effectively, one must identify the relevant objects and their locations within the document.
Manual Extraction Techniques
For simple PDFs or when dealing with a small amount of data, manual extraction methods might suffice. The most basic approach involves copying and pasting text directly from the PDF into another document or spreadsheet. While this works for small-scale tasks, it’s impractical for larger datasets due to its time-consuming nature.
Optical Character Recognition (OCR)
When dealing with scanned PDFs or documents containing images, Optical Character Recognition (OCR) becomes a lifesaver. OCR technology converts images of text into machine-encoded text, allowing for the extraction of data from scanned documents.
Several tools, both online and offline, offer OCR functionality. Software like Adobe Acrobat, ABBYY FineReader, and Google Drive’s built-in OCR feature are popular choices. Simply upload your PDF, run the OCR process, and watch as the text becomes searchable and extractable.
Python Libraries to Extract Data From PDFs
For those comfortable with programming, Python offers powerful libraries that streamline the process of extracting data from PDFs. Two prominent libraries are PyPDF2 and PyMuPDF (MuPDF).
PyPDF2: This library allows you to extract text, merge, and split PDFs. It’s easy to use and works well for basic tasks. For instance, extracting text from a PDF using PyPDF2 involves opening the file, reading its content, and extracting the text.
import PyPDF2
pdf_file = open('example.pdf', 'rb')
pdf_reader = PyPDF2.PdfFileReader(pdf_file)
text = ""
for page_num in range(pdf_reader.numPages):
page = pdf_reader.getPage(page_num)
text += page.extractText()
pdf_file.close()
print(text)PyMuPDF (MuPDF): MuPDF is a more versatile library that not only extracts text but also allows for advanced operations like searching, highlighting, and annotating. Installing MuPDF and extracting text is straightforward.
import fitz
pdf_document = fitz.open('example.pdf')
text = ""
for page_num in range(pdf_document.page_count):
page = pdf_document[page_num]
text += page.get_text()
pdf_document.close()
print(text)Web Scraping PDF Data
When the aforementioned methods fall short or when dealing with dynamic PDFs embedded in websites, web scraping becomes a viable option. Selenium, a popular web automation tool, can be employed to interact with the webpage and extract data directly from the PDF element.
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
url = "https://example.com/pdf_page"
driver = webdriver.Chrome()
driver.get(url)
time.sleep(2) # Allow time for the PDF to load
pdf_element = driver.find_element_by_tag_name('embed')
pdf_text = pdf_element.text
print(pdf_text)
driver.quit()To extract data from PDFs may seem like navigating a labyrinth, but armed with the right tools and techniques, it becomes a manageable task. Whether opting for manual methods, OCR technology, Python libraries, or web scraping, the key is to choose the approach that best suits the complexity of the PDF document and your specific requirements.
By mastering the art of data extraction from PDFs, you empower yourself to efficiently handle information locked within these ubiquitous files, opening doors to enhanced productivity and streamlined data management. Happy extracting!
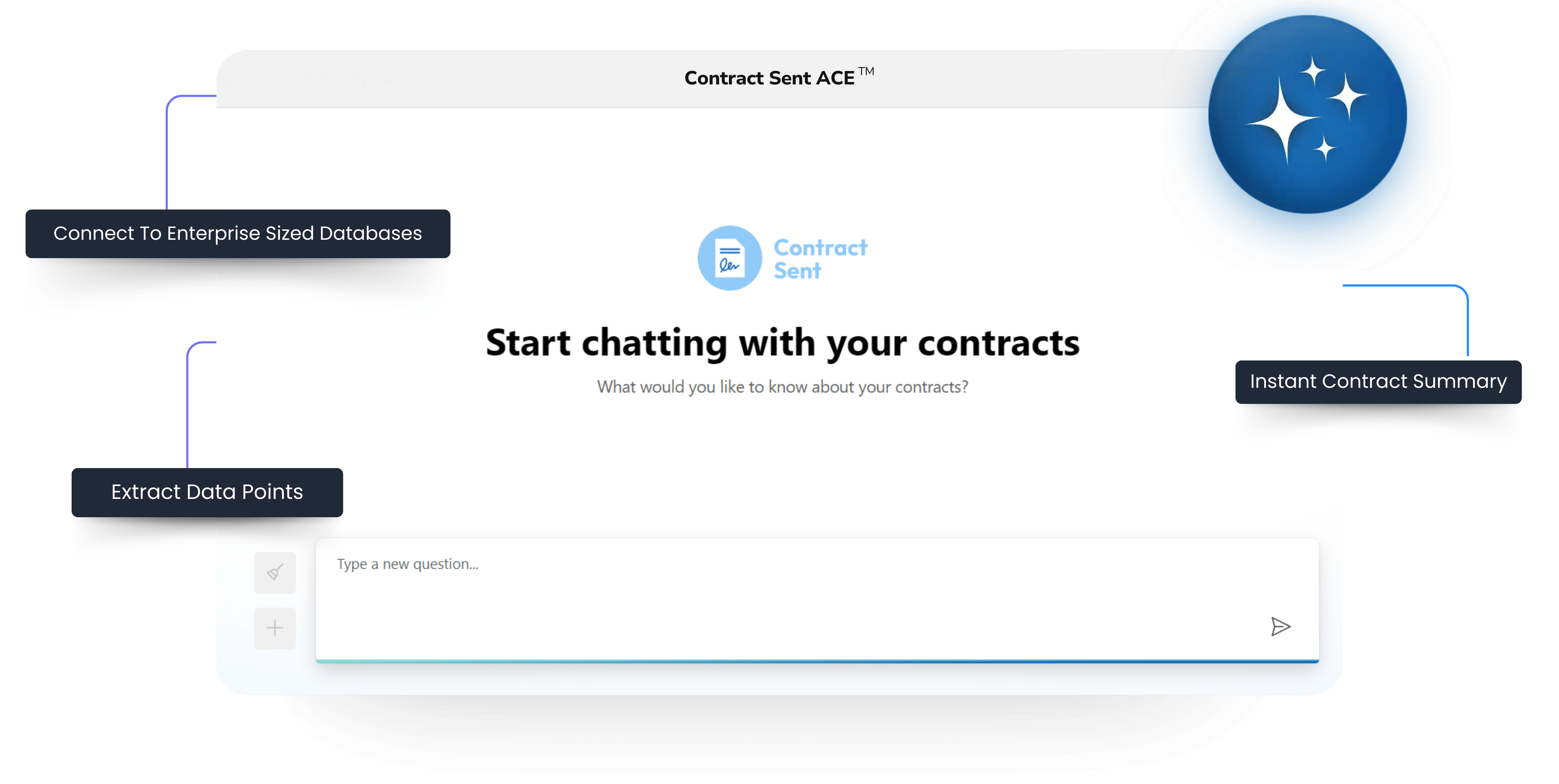
Basing Decisions on Contract Data With Contract Sent
When you’re scaling a company and starting a high volume go to market strategy businesses need solutions that not only address current challenges but also pave the way for future growth. Extracting data from your documents and integrating this with contract management system like Contract Sent, startups can navigate contract negotiations with newfound efficiency, reducing sales cycles and propelling their growth trajectory.
The combination of Contract Sent’s innovative features and the ability to extract valuable data from PDFs is a path to scale for businesses, offering a solution to the manual challenges of sales.